PCA-EVAL is an innovative benchmark for evaluating multi-domain embodied decision-making, specifically focusing on the performance in perception, cognition, and action. It is proposed in paper “Towards End-to-End Embodied Decision Making via Multi-modal Large Language Model: Explorations with GPT4-Vision and Beyond”.
Peiyi Wang1, Tianyu Liu2, Baobao Chang1
1Peking University, 2Tencent Cloud AI
Table of contents
Domains and Examples
Initially, PCA-EVAL benchmarks three domains to evaluate the general embodied decision-making capabilities of agents. As shown below, these domains include Autonomous Driving, Domestic Robot and Open-World Game.
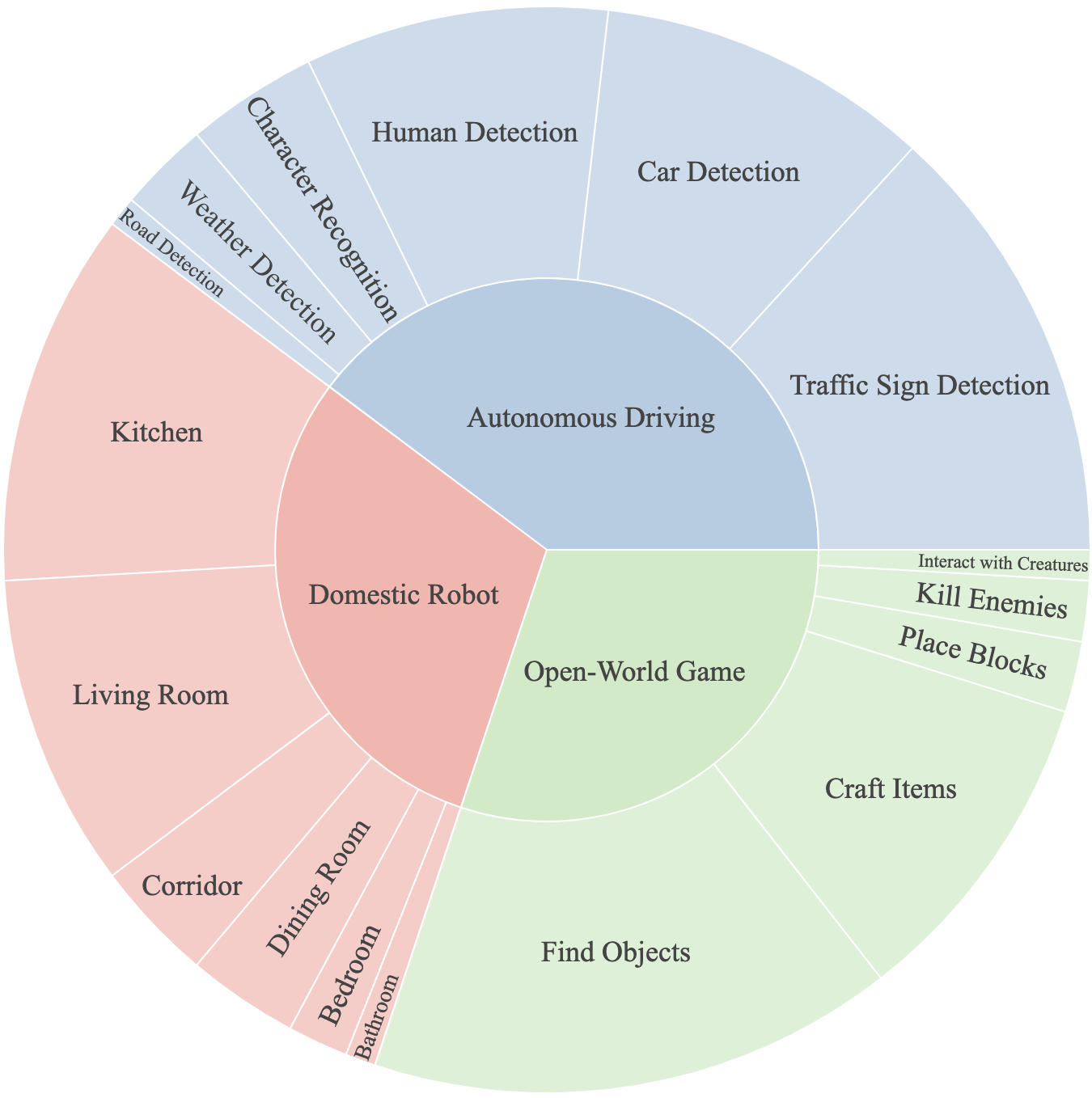
Domain and required ability distribution of PCA-EVAL.
For each domain, we give three examples below.
- Autonomous Driving Domain

- Domestic Robot Domain

- Open-World Game Domain

Metrics
- Perception-Score: Evaluate whether the agent captures the key concepts related to the question in the observation.
- Cognition-Score: Evaluate whether the agent makes correct deduction with perception and world knowledge to the final action.
- Action-Score: Evaluate whether the agent chooses the correct action.
Each score is either 0 or 1 for an agent’s response to a question. The scores of all instances are averaged to get the final performance.
Methods
We evaluate two methods with different models on our PCA-EVAL benchmark. We provide evaluation guidelines in Run Evaluation.
End2End
End2End embodied decision making is straightforward since we can directly feed the visual observation and the textual question to the multi-modal agent. As illustrated in the figure below, the agent is prompted to output the image description and reasoning process before giving the final action.

Example of End2End Decision Making
HOLMES
Within HOLMES, we prompt large language models like ChatGPT-3.5, GPT4 to call different visual models or APIs to gather information about the environment. In our evaluation toolkit, the results of all API calling are cached so the users do not need to implement the API themselves.

Example of HOLMES
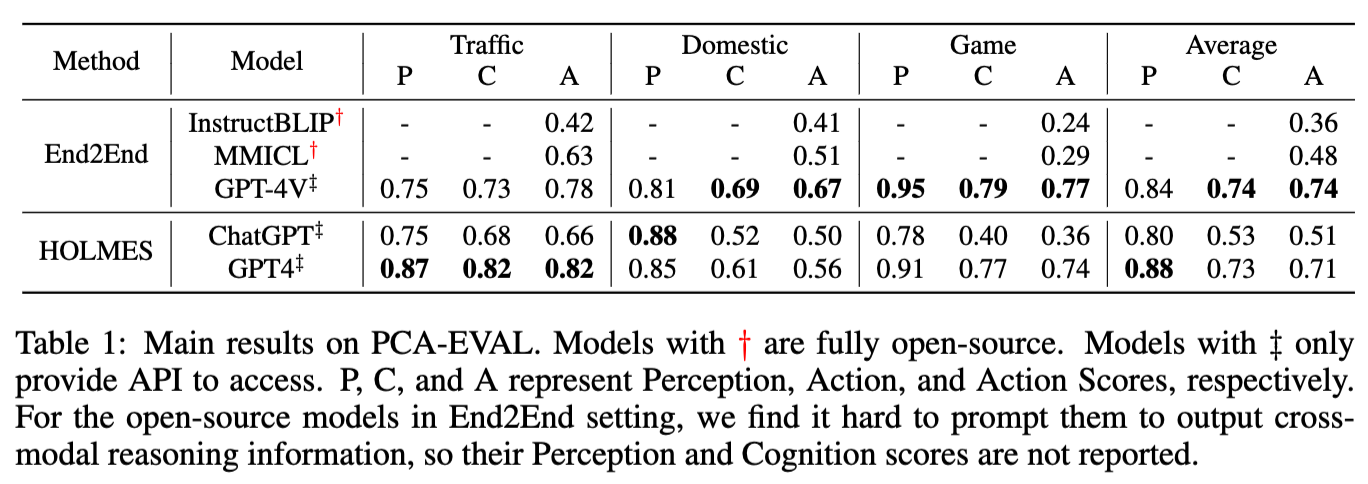
Results
Citation
@article{chen2023endtoend,
title={Towards End-to-End Embodied Decision Making via Multi-modal Large Language Model: Explorations with GPT4-Vision and Beyond},
author={Liang Chen and Yichi Zhang and Shuhuai Ren and Haozhe Zhao and Zefan Cai and Yuchi Wang and Peiyi Wang and Tianyu Liu and Baobao Chang},
year={2023},
journal={ArXiv},
}